
The new Azure Synapse Analytics SQL Serverless service enables querying file-based data stored in an Azure Data Lake Gen2 storage account by using familiar T-SQL. The data remains stored in the source storage account and CSV, Parquet and JSON are currently supported file types. The service enables data roles such as Data Engineers and Data Analysts to query from storage and also to write data back to storage.
The pricing mechanism is based on the volume of data processed rather than service tiers or uptime. The current cost is £3.727 ($5) per 1 Terabyte (TB) processed. Please note that this cost is not a minimum cost, you are therefore able to run queries that process far less data and are charged appropriately. E.G. if you run a query that processes 100GB of data you will be charged ~£0.3727. Data processing costs include retrieving the data from storage, reading any file metadata, data transfer between processing nodes, and returning the results to the SQL Serverless endpoint. The SQL Serverless service has been Generally Available (GA) since November 2020.
Scenario
In this scenario we’ll be creating:
- An Azure Data Lake Gen2 storage account to store both CSV and Parquet files
- An Azure Synapse Analytics workspace with the SQL Serverless engine
- 2 External SQL tables to query the CSV and Parquet data by using T-SQL.
Azure Synapse Analytics
Prerequisites & Cost
To follow along with the walkthrough, you’ll need access to an Azure Subscription with permissions to create resources. There are no costs associated with creating the initial Synapse Analytics workspace, however there are storage costs and SQL Serverless costs. This blog post will incure less than £1 of costs to run through the example. Pricing is available in the References section of this blog post.
Walkthrough
We’ll now walk through the steps necessary to create the Azure resources. The References section at the end of this blog post contains links to official documentation which expand on the features in this blog post.
Create Azure Services
Resource Group
- Login to the Azure portal at https://portal.azure.com
- Create a new Resource Group (search for the term in the search bar) by clicking Add in the Resource Group section.
- Select the appropriate subscription to store the Resource Group in and choose a region. Please ensure that the same region is selected in all subsequent steps.
Storage Account Creation
- Create a new Storage account by clicking Add in the Storage accounts section.
- Enter the following information on the Basics tab:
- Subscription: Your appropriate subscription.
- Resource Group: Select the Resource Group created in the previous step.
- Storage account name: Enter an appropriate name such as storsynapsedemo.
- Location: Select the same region as the Resource Group
- Performance: Standard
- Account kind: StorageV2
- Replication: Zone-redundant storage
- Enter the following information on the Networking tab:
- Connectivity method: Public endpoint (all networks) – suitable for development purposes.
- Network routing: Microsoft network routing (default)
- Enter the following information on the Advanced tab:
- Blob Storage: Allow Blob public access: Disabled
- Data Lake Storage Gen2 Hierarchical Namespace: Enabled
- Select Review + Create then after successful validation, select Create.
After the new storage account has been created, we need to add a new container and folder structure.
- In the new storage account, select Containers in the Data Lake Storage section.
- Select + Container to create a new container called datalakehouse.
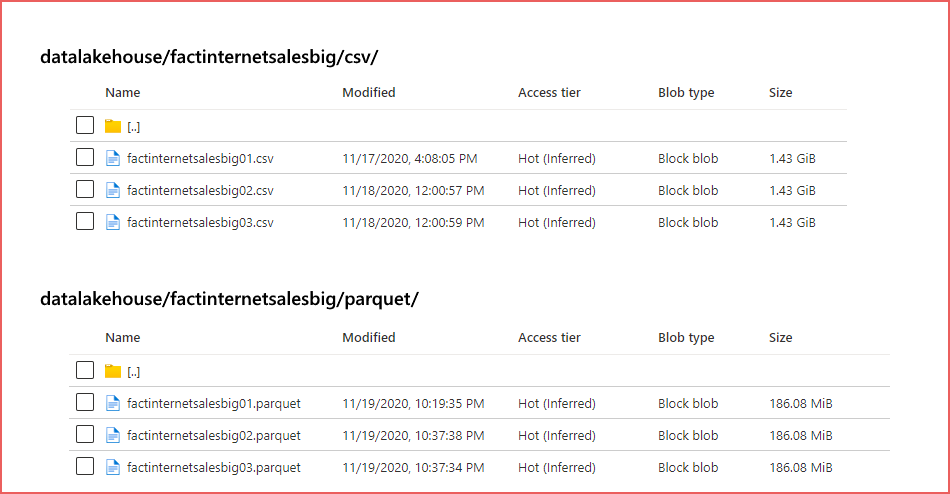
- Click into the new container and select + Add Directory and enter factinternetsalesbig as the name.
- Create 2 new folders called csv and parquet in the factinternetsalesbig folder.
The data itself is based on the FactInternetSales data from the AdventureWorksDW example Microsoft database. There is a single CSV (comma separated values) file and a single Parquet (compressed columnstore binary file format) file available here in GitHub. You can create multiple copies of each file and upload to the appropriate folder in the storage account. In this demo we are using 3 copies of each file however the example files on GitHub are smaller due to file size limitations. The process is the same except for the file sizes.
Synapse Analytics Workspace
- Create a new Synapse Analytics Workspace by searching for Synapse Analytics and selecting Azure Synapse Analytics (workspaces preview)
- Select Add and enter the following information on the Basics tab:
- Subscription: Your appropriate subscription.
- Resource Group: Select the Resource Group created in the previous step.
- Workspace Name: Choose an appropriate name.
- Region: Select the same region as the Resource Group.
- Select Data Lake Storage Gen2 Account Name: Select Create new and enter an appropriate name.
- File system name: Select Create new and enter users.
- Enter the following information on the Security tab
- SQL Administrator Admin username: Enter an appropriate username for the SQL administrator account.
- Password: Enter an appropriate password (and confirm).
- Enter the following information on the Networking tab:
- Disable the Allow connections from all IP Addresses checkbox
- Select Review + Create then after successful validation, select Create.
When the Synapse Analytics Workspace has been created, a Firewall rule will need to be added to ensure you can connect to the service.
- In the new Synapse Analytics Workspace section in the Azure portal, select Firewalls under the Security section.
- Ensure that Allow Azure services and resources to access this workspace is set to On.
- Enter your Client IP Address into the Start IP and End IP textboxes and give the rule an appropriate name.
Security Configuration
We’ll be using User-based security to access the storage account from SQL Serverless, therefore the user account which will be used to create the Dataflow will need appropriate permissions.
- In the Storage account created at the start of the process, select Access Control (IAM) and click Add > Add Role Assignment
- Ensure the user account is assigned to the Storage Blob Data Contributor role and save.
- The security changes can take a few minutes to activate.
SQL Serverless Database and SQL Objects
We can now create SQL objects within the SQL Serverless environment which will be used by the Dataflow.
- Browse to the Synapse Analytics Workspace in the Azure Portal.
- In the Overview section, click the link in the Workspace web URL field to open the Synapse Analytics Studio.
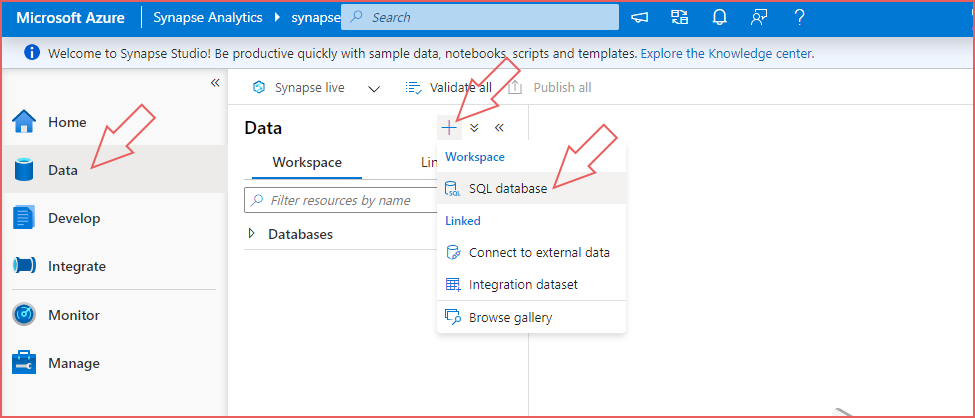
- Expand the left-hand menu and select the Data section.
- Select the + icon and select SQL database.
- Ensure that Serverless is selected in the Select SQL Pool type option and enter a name, e.g. sqldatalakehouse.
Now that a new SQL Serverless database has been created, we will create the necessary SQL objects to allow us to read (SELECT) data from the storage accounts.
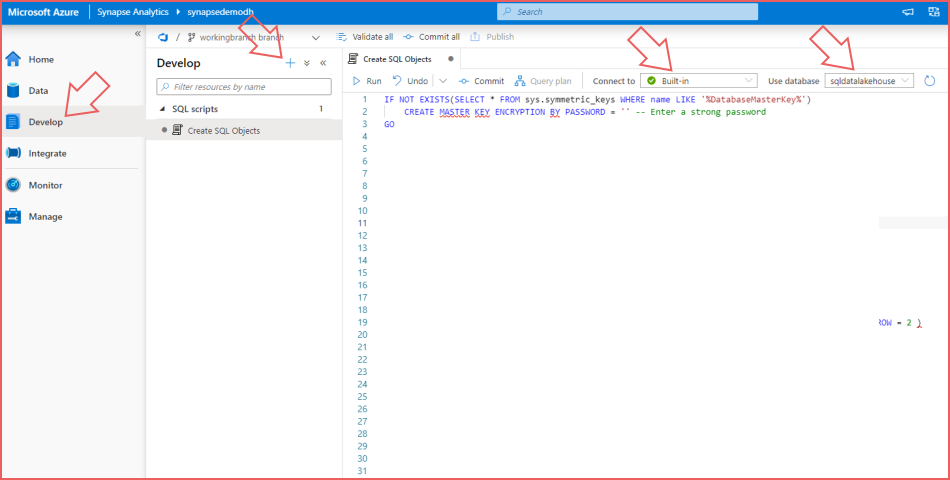
- Select the Develop section on the left-hand Synapse Studio menu.
- Select the + icon and select SQL script.
- In the Properties window to the right, give the script a name such as Create SQL Objects.
- Ensure that Connect to is set to Built-in.
- Ensure that Use database is set to sqldatalakehouse (or the name given to the new SQL Serverless database).
The following SQL code can be copied into the blank Create SQL Objects script and run individually. Alternatively you can create a new script file in Synapse Studio for each statement.
Create Database Master Key
IF NOT EXISTS(SELECT * FROM sys.symmetric_keys WHERE name LIKE '%DatabaseMasterKey%')
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<STRONG_PASSWORD>';Create Database Scoped Credential
IF NOT EXISTS(SELECT * FROM sys.database_credentials WHERE name = 'SynapseUserIdentity')
CREATE DATABASE SCOPED CREDENTIAL SynapseUserIdentity WITH IDENTITY = 'User Identity'
;Create External File Formats for CSV and Parquet
IF NOT EXISTS (SELECT * FROM sys.external_file_formats WHERE name = 'SynapseParquetFormat')
CREATE EXTERNAL FILE FORMAT SynapseParquetFormat
WITH ( FORMAT_TYPE = PARQUET)
;
IF NOT EXISTS (SELECT * FROM sys.external_file_formats WHERE name = 'QuotedCsvWithHeaderFormat')
CREATE EXTERNAL FILE FORMAT QuotedCsvWithHeaderFormat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS ( PARSER_VERSION = '2.0',FIELD_TERMINATOR = '|', STRING_DELIMITER = '"', FIRST_ROW = 2 )
);
Create External Data Source
The <STORAGE_ACCOUNT_NAME> name will be the storage account name created in the Storage Account Creation section, not the Synapse Workspace section as this is where the CSV and Parquet data are stored.
IF NOT EXISTS (SELECT * FROM sys.external_data_sources WHERE name = 'storagedatalakehouse')
CREATE EXTERNAL DATA SOURCE storagedatalakehouse
WITH (
LOCATION = 'https://<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/datalakehouse')
;Create External Table for CSV and Parquet Files
The following 2 SQL scripts create External Tables which are tables that can be queried the same as regular tables but the data remains in the storage account, it is not loaded into these types if tables. SQL Serverless only supports External Tables.
CREATE EXTERNAL TABLE DW.FactInternetSalesBig (
ProductKey INT,
OrderDateKey INT,
DueDateKey INT,
ShipDateKey INT,
CustomerKey INT,
PromotionKey INT,
CurrencyKey INT,
SalesTerritoryKey INT,
SalesOrderNumber NVARCHAR(20),
SalesOrderLineNumber TINYINT,
RevisionNumber TINYINT,
OrderQuantity SMALLINT,
UnitPrice DECIMAL(10,4),
ExtendedAmount DECIMAL(10,4),
UnitPriceDiscountPct FLOAT,
DiscountAmount FLOAT,
ProductStandardCost DECIMAL(10,4),
TotalProductCost DECIMAL(10,4),
SalesAmount DECIMAL(10,4),
TaxAmt DECIMAL(10,4),
Freight DECIMAL(10,4),
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25),
OrderDate DATETIME2(7),
DueDate DATETIME2(7),
ShipDate DATETIME2(7)
) WITH (
LOCATION = '/factinternetsalesbig/csv',
DATA_SOURCE = storagedatalakehouse,
FILE_FORMAT = QuotedCsvWithHeaderFormat
);CREATE EXTERNAL TABLE DW.FactInternetSalesBigParquet (
ProductKey INT,
OrderDateKey INT,
DueDateKey INT,
ShipDateKey INT,
CustomerKey INT,
PromotionKey INT,
CurrencyKey INT,
SalesTerritoryKey INT,
SalesOrderNumber NVARCHAR(20),
SalesOrderLineNumber INT,
RevisionNumber INT,
OrderQuantity INT,
UnitPrice DECIMAL(10,4),
ExtendedAmount DECIMAL(10,4),
UnitPriceDiscountPct FLOAT,
DiscountAmount FLOAT,
ProductStandardCost DECIMAL(10,4),
TotalProductCost DECIMAL(10,4),
SalesAmount DECIMAL(10,4),
TaxAmt DECIMAL(10,4),
Freight DECIMAL(10,4),
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25),
OrderDate DATETIME2(7),
DueDate DATETIME2(7),
ShipDate DATETIME2(7)
) WITH (
LOCATION = '/factinternetsalesbig/parquet',
DATA_SOURCE = storagedatalakehouse,
FILE_FORMAT = SynapseParquetFormat
);Run SELECT to test access
SELECT TOP 10 * FROM DW.FactInternetSalesBig;
SELECT TOP 10 * FROM DW.FactInternetSalesBigParquet;We are now able to run T-SQL statements using the External Tables. These tables are accessible using SQL client tools like SQL Server Management Studio, Azure Data Studio and also Business Intelligence tools such as Power BI.
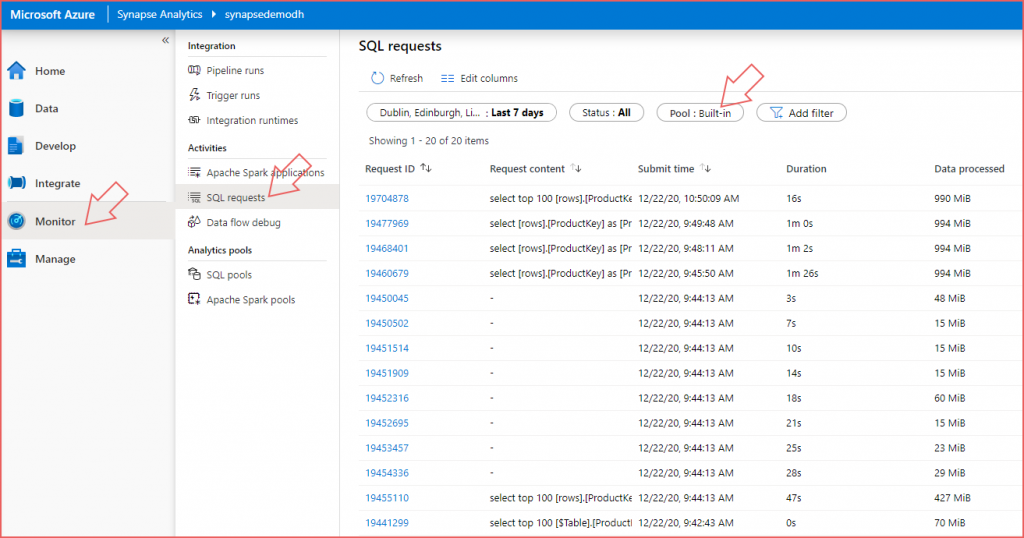
Data Processed Monitoring
The Monitor area within the Synapse Analytics Studio contains several sections for monitoring Synapse Analytics resources, including SQL Serverless. Click on the Monitor tab then click SQL requests under the Activities section. Ensure that the Pool filter is set to Built-in to show SQL Serverless queries. This shows the SQL queries issued which contains the query syntax and most importantly the Data Processed metric. Use this metric to determine the amount of data processed (and therefore chargeable) in your workloads. Use this metric to plan workload costs.
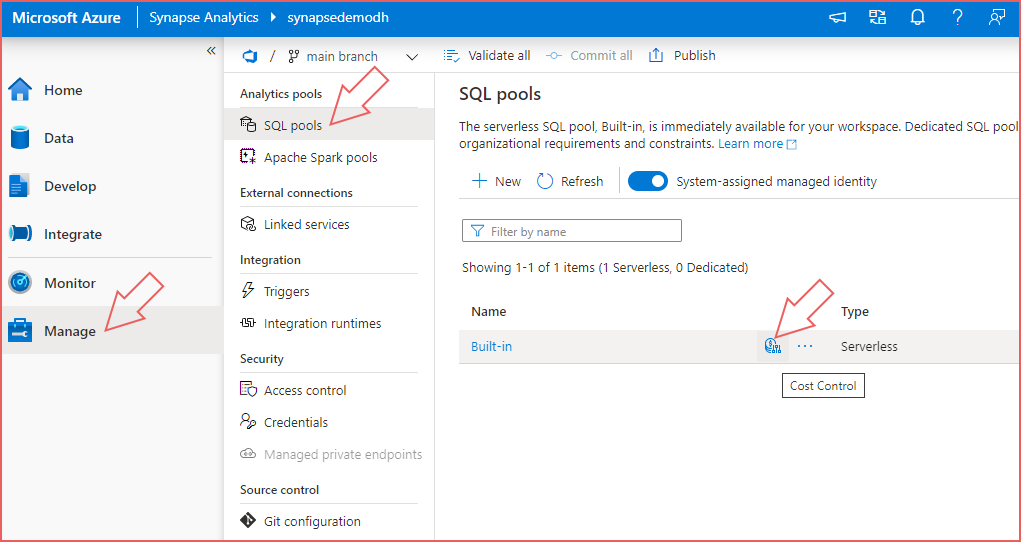
Data Processed Cost Control
To ensure that no unexpectected costs arise from using the SQL Serverless engine, there is a Cost Control feature in the Manage > SQL Pools area (shown in the image below). Select this feature and add Daily, Weekly and Monthly limits in increments of 1 (Terabyte). E.G set 1 for Daily, 2 for Weekly and 4 for Monthly to ensure that your daily data processed does not exceed 1 TB, Weekly does not exceed 2TB and monthly does not exceed 4TB.
Clean Up
To remove the Azure resources, delete the Resource Group created at the beginning of this walkthrough. All resources within this Resource Group will be deleted.
References
- https://docs.microsoft.com/en-us/azure/synapse-analytics/quickstart-create-workspace
- https://docs.microsoft.com/en-us/azure/synapse-analytics/quickstart-sql-on-demand
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/create-use-external-tables
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-storage-files-storage-access-control?tabs=user-identity
- https://docs.microsoft.com/en-us/power-bi/transform-model/dataflows/dataflows-introduction-self-service
- https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/data-processed
- https://azure.microsoft.com/en-us/pricing/details/storage/data-lake/